


전체작품 보기


이예림
Rule-Based Scoring과 Graph Pattern Analysis를 통합한 블록체인 AML 탐지 시스템
본 연구는 블록체인에서 발생하는 자금세탁을 탐지하기 위해 룰 기반 분석과 그래프 패턴 분석을 결합한 2단계 하이브리드 AML 시스템을 개발하였다. 22개 룰로 구성된 룰북을 설계하고, PPR과 Layering·Cycle·Fan-in/out 등 그래프 기반 패턴을 탐지해 1단계 해석 가능한 점수를 생성하였다. 이를 기반으로 Gradient Boosting 등 머신러닝을 적용해 2단계 최종 스코어를 산출한 결과, Accuracy 99.20%, ROC-AUC 0.9992로 기존 모델을 능가하는 성능을 달성하였다. 실시간 분석(Basic 1~5초)도 가능해 CEX·규제기관 환경에 즉시 적용 가능한 시스템으로 확장 잠재력을 갖는다.
이호진
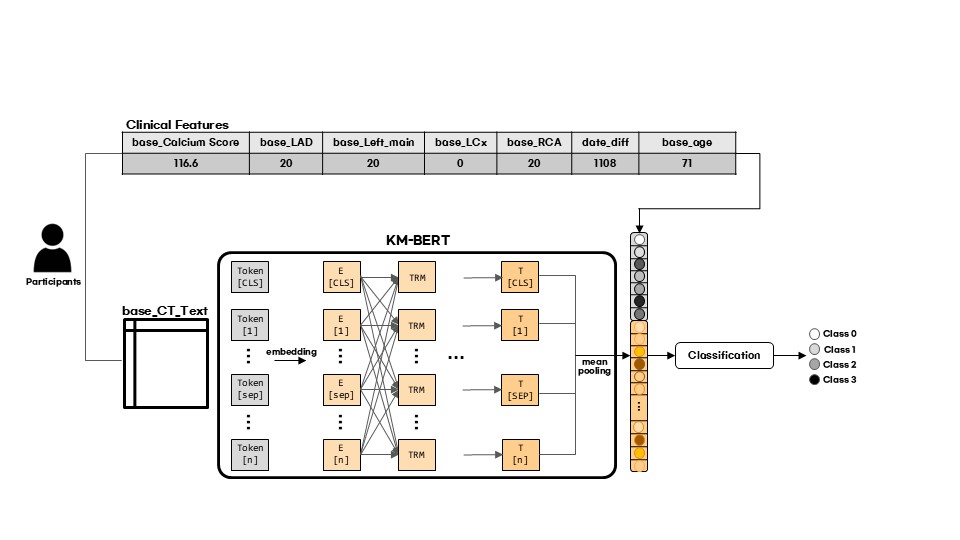
XAI Based Multimodal Feature Extraction for Retrospective Estimation of Coronary
본 연구에서는 semantic feature가 포함된 CT Report Text와 임상데이터(Clinical Feature)를 함께 활용하여 미래 시점 CAC Score의 예측 정확도를 향상시키고 결과를 후향적으로 추정하여 Shap Value, Feature Importance 등을 활용하여 XAI 기반 멀티모달 모델로 확장을 하고자 하였다. 이를 통해 성능에 영향을 미치는 주요 feature를 탐색함으로써 모델의 해석 가능성과 임상적 활용 가능성을 높이고자 하였다

구병우
치기공 응용을 위한 치아 색상 보정 기술 개발
본 프로젝트는 치과와 치기공사 간의 조명 환경, 카메라, 촬영장비 차이로 발생하는 치아 색상 정보의 왜곡을 해결하기 위한 솔루션 개발의 사전 연구임. ‘최대한 유사한 촬영 환경’을 제안하고 촬영 조건을 표준화하여 이미지 프로세싱 기술을 활용한 공통 색상 보정 솔루션을 적용하여 조금 더 정확한 심미 보철물 제작을 돕고 의사소통 비용을 줄이는 것이 본 연구의 목적임.
김진영
Zipf 분포 기반 메모리 접근 패턴에서의 MGLRU 페이지 교체 알고리즘 성능 분석
본 연구는 메모리 접근 패턴에 기반하여 페이지 교체 알고리즘인 MGLRU의 성능을 분석하는 것을 목표로 한다. 이를 위해 데이터베이스의 메모리 접근 패턴을 분석을 기반으로 성능 비교 실험을 진행하였다. 결과적으로 직접 설계한 실험에서 이점을 보였으나, 실제 애플리케이션 테스트에서는 큰 차이를 확인할 수 없었다.

이호진
Longitudinal Forecasting of Coronary Artery Calcium
본 연구는 관상동맥(Coronary Artery)에서 심혈관 질환 위험을 정량화 하는 Calcium Score를 보다 정확하게 예측하기 위해 임상데이터(Clinical Feature)와 CT Report Text를 함께 사용하는 멀티모달 모델을 구축하여 더 좋은 예측 성능을 보이고자 하였습니다. 연구에서 Regression과 Classification 두 가지 관점에서 traditional ML 모델을 사용함으로써 모뎅 성능을 비교했고 이를 통해 추후에 제안하고자 하는 모델과 비교할 Baseline 모델을 마련했습니다.

박영진
Multi node graph partitioning을 위한 기반 통신으로서의 MPI 구현
분산 메모리 환경에서 대규모 그래프 파티셔닝 수행 시, 빈번한 정보 교환과 동기화는 시스템 성능과 확장성을 저해하는 주요 병목 요인이다. 이에 본 연구는 통신 오버헤드를 효과적으로 완화하고 대규모 그래프 처리 성능을 극대화하기 위해, 최적화된 MPI 기반 통신 모델을 제안한다.


김민창
GPU-Optimized Label Propagation for Large-Scale Graphs via Warp-Cooperative Ke
본 작품은 대규모 그래프 파티셔닝 프레임워크 DMOLP에서 경계(boundary) 노드 라벨 전파를 GPU에 최적화한 CUDA 커널 구현이다. 경계 중심 서브그래프를 구성하고 warp-per-node 방식과 shared memory 기반 라벨 집계를 적용하여 메모리 전송량과 warp divergence를 줄이고, GPU에서의 실행 시간을 단축하도록 설계하였다.

김명준
Federated Learning IoT Platform AI Technology Research
연합학습은 분산 환경에서 개인정보에 대한 프라이버시를 지키면서 AI의 학습을 위해 고안된 기술로, 특히 차량과 같이 민감한 위치정보와 주행 영상이 포함된 환경에서 프라이버시 보호가 필수적이며, 지역별로 다른 도로 환경 데이터를 효과적으로 활용하기에 적합하다. 본 프로젝트에서는 이전 프로젝트에서 구축한 연합학습 IoT 플랫폼을 차량용 이미지 도메인으로 확장하여, 도시 장면 데이터셋을 활용한 Segmentation 모델을 구현하는 것을 목표로 한다. 또한 지식 증류를 적용하여 non-IID 환경에서도 성능 저하를 최소화하는 방안을 모색한다